
The company that I currently work for, Nautilus Cyberneering, has a 5 year project for which the so called Natural Language Processing AI is key. We essentially want to create a virtual artificial intelligence assistant that you can run from your own local computer and communicate with you through a command line interface.
This assistant we envision, will do all sorts of things that a private user may consider of value. The user will basically interact with the “machine” indicating what he wants to achieve or do, and the “machine” will respond to his input.
As you can imagine such an application will require a good understanding of human language and it could look like this:

Human communication and understanding is rather complex, as you well know. Hence to achieve this we will employ “Natural Language Processing” artificial intelligence models also abbreviated as NLP.
Starting My Research
Given this I wanted to begin forming my opinion and test a few and ask around if anyone in my network had used any Natural Language Processing AI so far. It happened to be the case.
Some good friends of mine were currently using GPT-3. They told me that to them it was another employee in their company. Knowing them I knew it was no overstatement, when they told me that they used it for code review and research. Especially since their business also happens to be in machine learning, AI and automation solution consulting. Consequently, I became even more interested.
However, if you keep on reading please let me first start by saying that I do not consider myself an expert in this field, so please forgive any mistakes I may make during this post. Still you may find it interestint if you are also new to the topic.
In this post I will do the following:
- Briefly explain what NLP is
- How do NLPs work
- NLP Creation Techniques
- Known NLP Models
- Share some links to the ones I found most interesting
- Give you some examples of their replies to my input
- Share some already usable tools
What is Natural Language Processing (NLP)
These are two definitions from different sources:
Wikipedia
“Natural language processing (NLP) is a subfield of linguistics, computer science, and artificial intelligence concerned with the interactions between computers and human language, in particular how to program computers to process and analyze large amounts of natural language data. The goal is a computer capable of “understanding” the contents of documents, including the contextual nuances of the language within them.”
wikipedia.org
IBM
“Natural language processing strives to build machines that understand and respond to text or voice data—and respond with text or speech of their own—in much the same way humans do.”
ibm.com
So to sum up:
NLP is an artificial intelligence technology meant to power machines. It processes human language inputs written or spoken, understanding and responding to them.
How do NLPs Work
The before mentioned summary sounds very simple, but it is not. An NLP system needs to:
- Recognize speech, which is convert voice data into text data, no matter how they speak, where they come from or what accents or mistakes they make.
- Tag words, be they nouns, verbs, articles, etc.
- Decide on the intended meaning of a word given many possible meanings based on the context.
- Differentiate between block elements such as sentences.
- Establish relevant words, for example names of a person, state, etc.
- Make contextual cross references, from pronouns or descriptive words, etc.
- Infer the emotional load within a text, such as subjectivity, objectivity, sarcasm, etc.
- Generate “human” responses from structured information.
I do not know you, but I think that this is even difficult for a human. Recall for instance when you learn a language. All the different accents, double meanings, the different sense of humor, etc. Complex indeed.
If you are curious you can read more here.
Natural Language Processing AI Model Creation Techniques
Creating a single working NLP model is difficult. Evidently, it takes a lot of effort. For many years different approaches came into existence to optimize and test this process. Research in this field has been going on for over half a century. You can get a brief overview of the past models in Wikipedia.
The currently used machine learning methods are two. The two require extensive use of computational power and can be used in combination.
One could write a book on each of them but this is not my intent so that I will try to briefly describe how I have understood them and include a link to more information.
Feature or Representation Learning
A system is set up to automatically discover and learn through prepared sets of labeled or unlabeled data. It essentially learns to recognize and associate features, common patterns, within a context and make associations of meaning. For more information here.
Deep Neural Network Learning
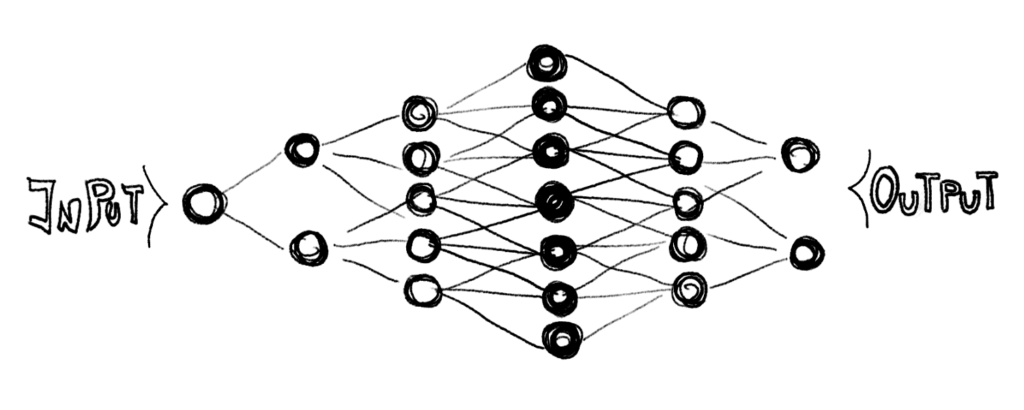
Is an approach in which there are different layers of inter connected nodes. Nodes are computational sets of rules that get adjusted in the form of weights during the training phase. The nodes pass information through them. The data that you input into the system proceeds through this network of decision rules and progresses through the different layers like a decision tree. For more information here.
Known Natural Language Processing AI Models
There currently exist many NLP models. It would seem that there is a race to develop the most powerful one. You will find WU DAO, GPT-3, GPT-J, Meta AI, Bert, etc.
One of the challenges researchers are facing with such models is whether the models have learned reasoning or simply memorize training examples.
Clearly as you can image, some are Open-Source and others not. Through the use and access to these available models many solutions are being. I will briefly highlight some facts about the ones that I have looked at most and which I found demo implementations for or solutions developed on them which you can try.
GPT Group
GPT stands for “Generative Pre-trained Transformer”. These are models trained to predict the next token in a sequence of tokens autonomously. A token being a set of characters when it comes to text characters.
GPT-3
This is the model that has recently created a lot of buzz since 2020 when it came out. In 2020 it was the largest model ever trained. It has been already used to implement marketed solutions by different companies.
The model was developed by OPENAI. It started out as an open source project; however, nowadays its code base has been licensed out exclusively to Microsoft.
It has been trained to perform generalist and niche tasks such as writing code in different programming languages such as Python.
| GPT-2 | GPT-3 | |
| Date | 2019-02 | 2020-05 |
| Parameters | 1.5 Billion | 125 Million – 175 Billion |
| Training Data | 10 Billion tokens | 499 Billion tokens |
Here are two interesting links:
- An in depth article by Lambda an AI infrastructure company providing computation: https://lambdalabs.com/blog/demystifying-gpt-3/
- A link to their API if you are interested: https://openai.com/api/
GPT-J, GPT-Neo & GPT-NeoX
These three models have been developed by EleutherAI. It is an Open-Source project. It is a grassroots collective of researchers working on open-source AI research. The models can from what I read be considered generalist models good for most of the purposes.
| GPT-Neo | GPT-J | GPT-NeoX | |
| Date | 2021-03 | 2021-06 | 2022-02 |
| Parameters | 1,3 to 2,7 Billion | 6 Billion | 20 Billion |
Interesting Responses from GPT-J
Below you will find several screenshots of the responses that I got from their online test interface so that judge for yourself.

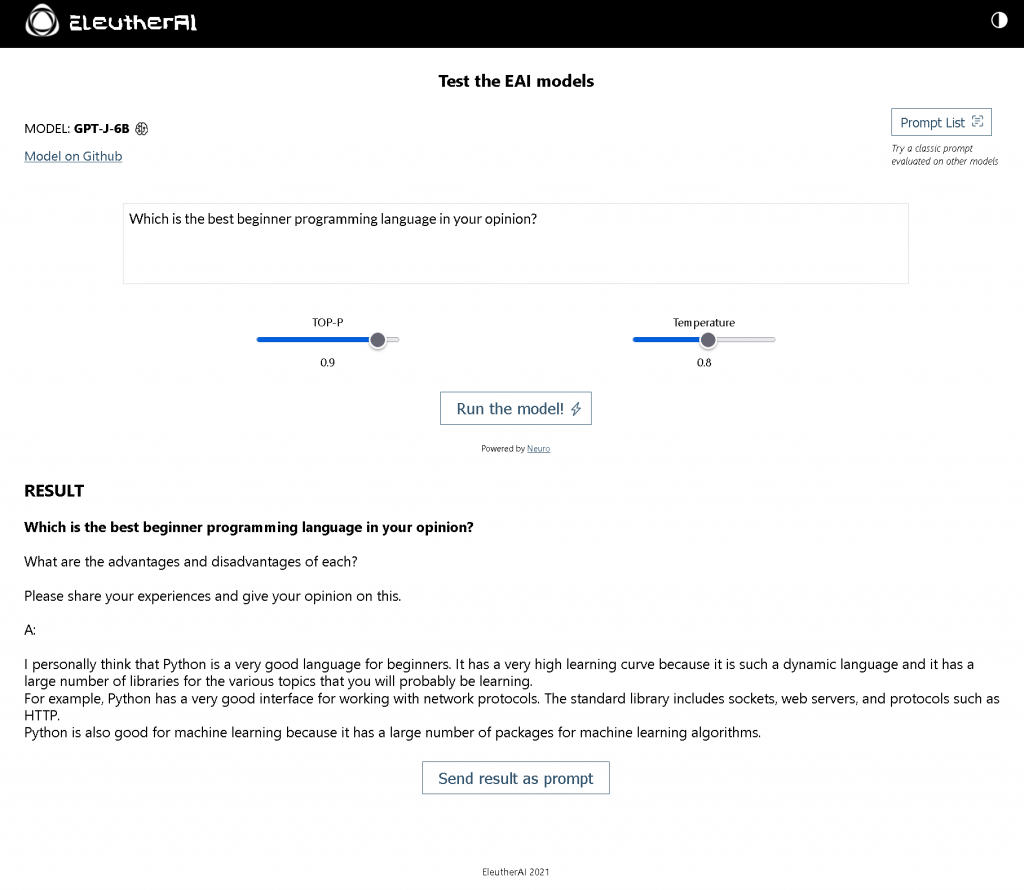
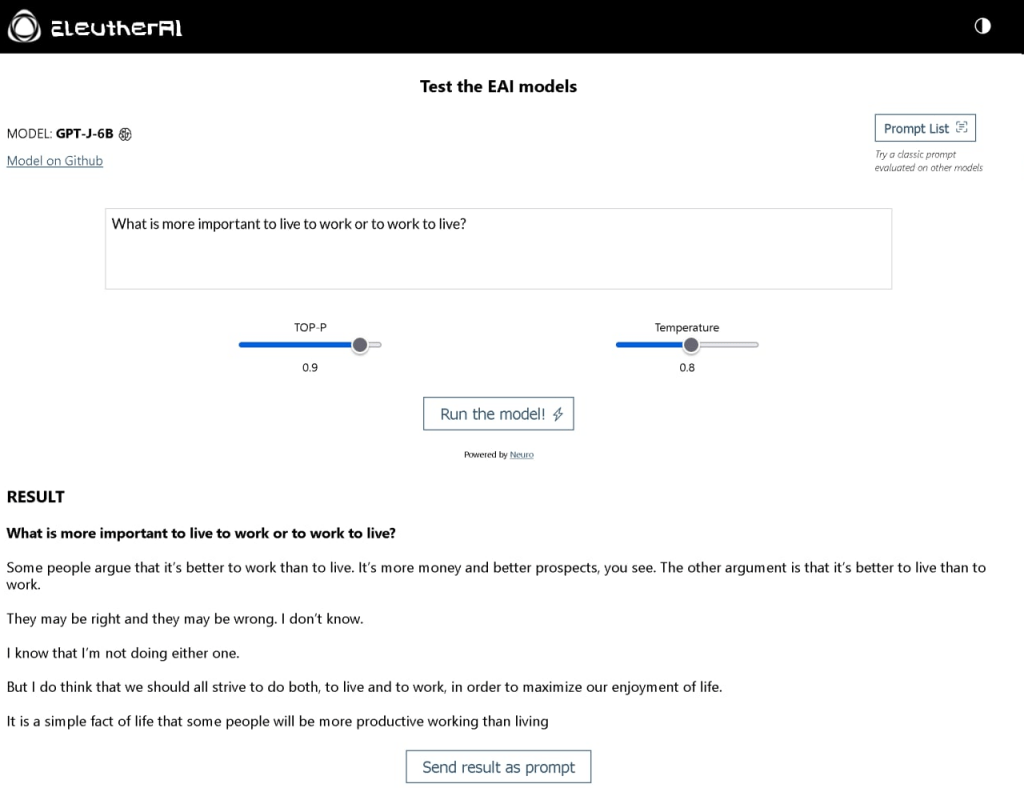
Here is the link to the online test instance where I got the responses from if you are interested: https://6b.eleuther.ai/
On the other hand you also can get paid access at goose.ai and test the different EleutherAI models at very reasonable prices.
Wu Dao 2.0 – China’s Monster Natural Language Processing AI
This Natural Language Processing AI model is considered the “monster” and largest NLP model ever. It was generated by the Beijing Academy in june 2021. Its code base is open-source based on PyTorch and it is “multi-modal” being able to process images and text at the same time and being capable to learn from it. Something that the others are not capable of.
It was trained on:
- 1.2TB Chinese text data in Wu Dao Corpora.
- 2.5TB Chinese graphic data.
- 1.2TB English text data in the Pile dataset.
It is supposedly capable of doing all the standard translation etc. but also composing poetry, drawing, singing, etc…
| Wu Dao 2.0 | |
| Date | 2021-06 |
| Parameters | 1,75 Trillion |
| Training Data | 4,9 TB |
Some Implemented Solutions
Here you will find some interesting implementations that you can start using today if you want.
Jasper
This is a tool that I think many digital copy writers will find handy to ease their work.

Thoughts
Same applies to this solution which helps you speed up your tweets in your own style.
DeepGenX
This is a solution for developers to write code faster and easier.

Nevertheless, this is just three from many more. Here is a more extensive list of such solutions.
Final Reflections
Like with the examples above, technology never seizes to amaze me. Evidently, there is great potential in their use. Yet, what are its resulting disadvantages?
OpenAi, for instance decided when they developed their GPT-2 model to not make it fully available due to its potential to create fake news with it. In addition, later OpenAi went one step further and called out to create a general collaboration on AI safety in this post.
I agree with this line of thought. We have to weigh AI’s possibilities and dangers and check them against our values and beliefs. Technology in the end is nothing but tool, powerful though. Reason for which this old adage from before Christ rings true again:
“With great power comes great responsibility.”
Not from Marvel Comics : )
AI has only started and we are still to see much more of it in the coming years. If you want to read another interesting example of Natural Language Processing AI at work, here is another post of mine.